The best software gets built by people who understand the problem at the deepest level. The same person reading the research paper is writing the model, shipping the code, and sitting with the end user when it goes live. When those activities happen in one team, the output quality goes up and the timeline collapses.
That's what 360 Labs is. We train custom models, publish the research, write production code, deploy on-premise, and maintain it. Same team. Same sprint.
In practice, this means a client goes from "we have a problem" to "here's a deployed system with a published technical report" in the time most companies take to finish a discovery phase.
We operate as opinionated technical partners. We co-build with organizations that bring deep domain expertise. You know your industry. We know how to build the software. The best products come from that collaboration.
We've done it across government ministries, public companies, hospitals, and high-growth startups. 21 of those projects are documented here.
• Large IT firms (Accenture, Deloitte, Infosys etc): scale headcount to implement pre-designed solutions. They optimize for delivery volume, not technical innovation. They're too slow and expensive for most businesses.
• Dev Shops and Software Agencies: build to spec and move on. No research arm, no IP retention, no long-term ownership of what they build. Also, no product and design taste.
• University Research Labs: produce research papers and prototypes, but almost none of it reaches scale and production. The ideas are strong, but the engineering to ship them at scale doesn't exist inside academia.
Studied Mathematics at the University of Toronto (with modules in Psychology, Philosophy, and Computer Science), then IT and Digital Innovation at City, University of London with a focus on AI and Product Design. Worked closely with the founding team at DeepReel.com, navigating their last $1M fundraise.
Joined brdge.ai as the first employee in London and helped grow it to $900K+ ARR in under 6 months, managing a team of 10. Built two AI-native SaaS startups during and after university, shipping MVPs and getting initial traction and users for both. Runs 360 Labs.
Hardware engineer turned AI researcher turned full-stack software engineer. Started writing system-level code in C++ and Rust building JAR applications for devices in the pre-smartphone era. Contributed the browser module to BossOS, India's national open-source operating system deployed across 6M+ government devices for CDAC. Built weather prediction algorithms for the Indian Meteorological Department.
Founded sociocats.co, a tech consulting and software development house serving Indian SMBs. Architected SLM360, India's first small language model: under 50MB, runs on less than 1GB of RAM, and outperforms every model globally at its size class, built for edge computing, defence, logistics, and aviation.
Case Studies
Technical deep-dives across healthcare AI, computer vision, edge computing, developer tooling, multi-agent systems, and operations platforms.
BOSS (Bharat Operating System Solutions) is developed by CDAC under the Ministry of Electronics and Information Technology, Government of India. It serves as India's national open-source OS, deployed across 6 million+ government offices, educational institutions, and public sector organizations. BOSS is built on Debian GNU/Linux and is available in 18+ Indian languages.
Developed and contributed the browser module for BOSS Linux. This is a core component of the desktop experience used across government installations nationwide. The browser module integrates with the BOSS desktop environment, handles web standards compliance, and supports Indian language rendering for regional scripts (Devanagari, Tamil, Bengali, etc.).
- Browser engine integration with BOSS Linux desktop environment
- Multi-script rendering support for 18+ Indian languages
- Compliance with government IT security standards
- Package management integration with BOSS software repositories
- Lightweight footprint for deployment on government-standard hardware
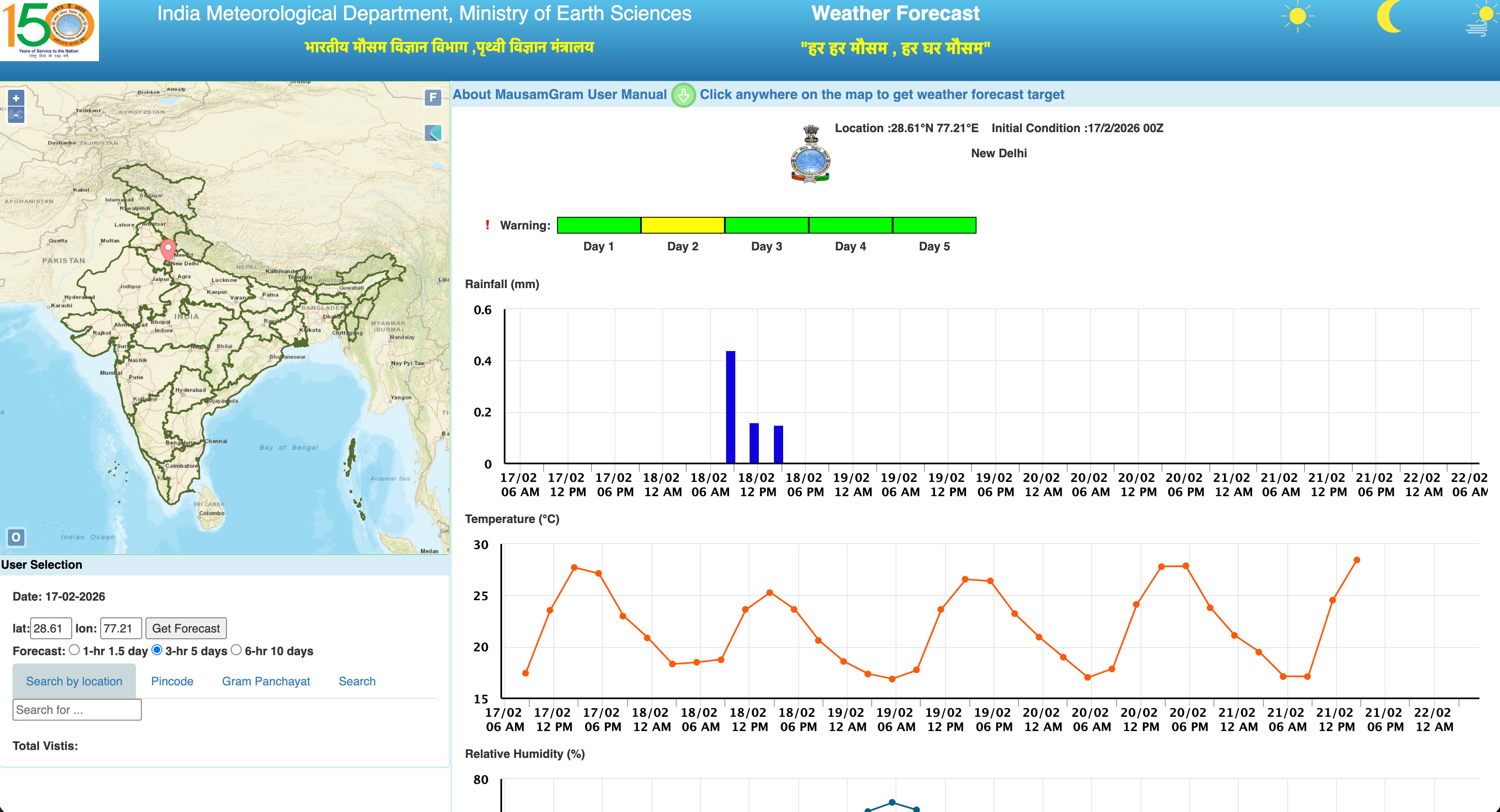
Developed weather analysis devices and prediction algorithms for the Indian Meteorological Department (IMD), Ministry of Earth Sciences, Government of India. IMD is responsible for weather observation, forecasting, and seismology across India. The system combines hardware sensor data acquisition with machine learning models for accurate weather prediction at the departmental level.
- Custom hardware weather analysis devices for environmental data collection (temperature, humidity, pressure, wind speed, precipitation)
- Sensor data ingestion pipeline with real-time telemetry and time-series storage
- ML prediction models: LSTM, GRU, and Transformer-based architectures for multi-horizon forecasting
- Feature engineering from raw sensor streams: rolling statistics, lag features, seasonal decomposition
- Integration with IMD's existing infrastructure and data formats
- Government-grade reliability, uptime, and accuracy requirements
Doctors spending more time writing clinical notes than seeing patients. 10+ hours/week per physician on manual documentation, leading to burnout, reduced throughput, and record errors. Needed automated medical transcription with EHR integration and HIPAA compliance.
Three-step workflow: Record, Transcribe, Submit. Audio captured and streamed to Google Chirp for medical speech-to-text, then Gemini 2.5 Pro generates structured SOAP notes, differential diagnoses, and medication lists in EHR-compatible formats.
Web Audio API with noise suppression. Streamed to Google Cloud Speech (Chirp) with medical vocabulary optimization and speaker diarization.
Gemini 2.5 Pro with medical prompt template. Fine-tuned on de-identified clinical notes to match major EHR formatting expectations.
- AES-256 at rest, TLS 1.3 in transit. Ephemeral processing, no PHI stored beyond session.
- Role-based access control, audit logging, BAA-covered Google Cloud.
Physiotherapy clinic drowning in manual processes. Hand-documented consultations, missed follow-ups, scattered treatment tracking. Hours daily on admin instead of patient care.
Add Patient > Start Consultation > Auto-Record > Generate Notes > Schedule Follow-ups. One-click start. OpenAI Whisper for real-time transcription, GPT-4 for structured clinical notes, automated appointment reminders from treatment plans.
Client-side audio via WebSocket to Python backend running Whisper. Real-time transcript with speaker identification.
GPT-4 with physiotherapy-specific prompts: chief complaint, objective findings, ROM measurements, home exercises in SOAP format.
- Treatment plans trigger appointment workflows automatically
- Multi-channel reminders (SMS + email), missed appointment detection
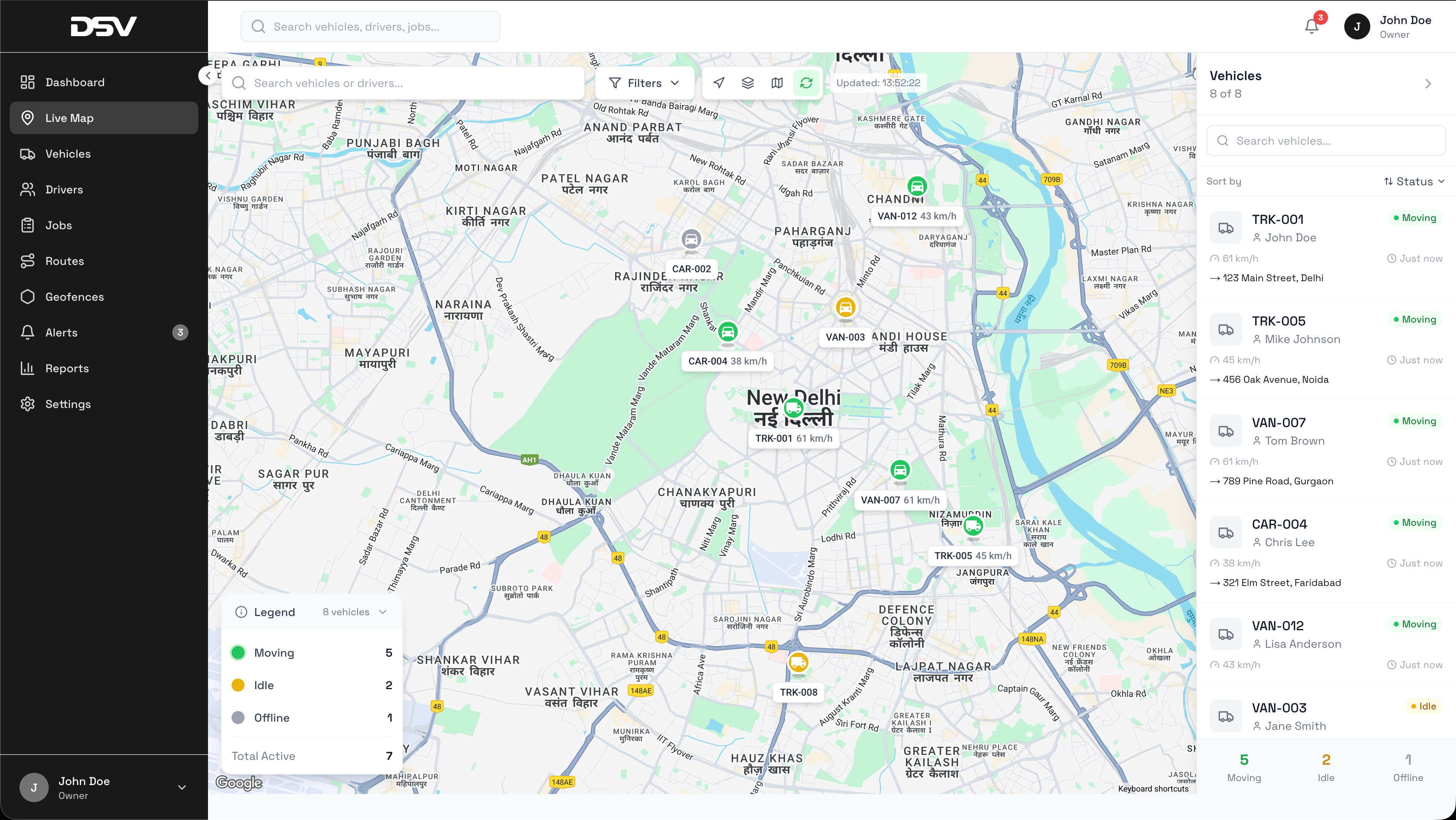
No centralized system for tracking vehicles or dispatching jobs. Unreachable drivers, manually planned routes, fuel waste, no fleet performance data. SLAs missed as fleet scaled.
Three-layer platform: web dashboard (live map), optimization engine (route planning), mobile driver app (field communication). Real-time GPS, geofencing, intelligent dispatching, fleet analytics.
GPS at 15s intervals via driver app. Firebase Realtime Database to web dashboard. Google Maps with custom markers, geofence polygons with entry/exit events.
Traffic-aware routing (Google Maps Directions API), vehicle capacity, time windows, hours-of-service. Nearest-neighbor + 2-opt improvement.
- Fleet performance dashboards, fuel monitoring, driver behavior scoring
- Maintenance scheduling by mileage and engine-hours
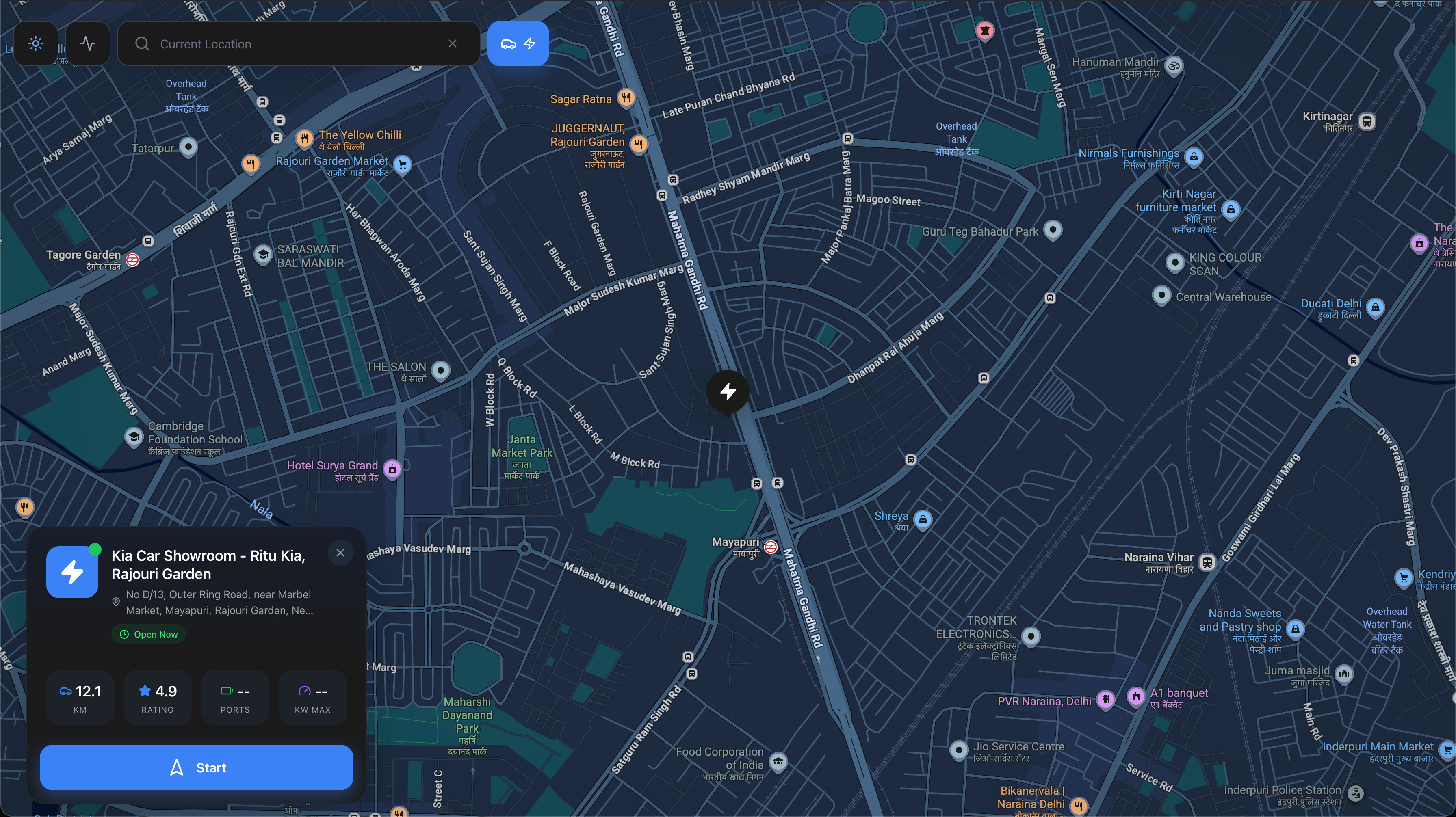
EV drivers had no way to find available stations. Showed up to find chargers occupied or incompatible. No real-time availability data, high support ticket volume.
Station finder aggregating connector types, speeds, live availability, user reviews. Web app + Flutter mobile app with voice-guided navigation and offline map caching.
OCPP backend providing real-time connector status. Google Maps for geospatial queries. Filters: CCS, CHAdeMO, Type 2, speed, availability.
Traffic-aware routing via Directions API. Mobile: voice-guided turn-by-turn, offline tile caching.
- Charging session history with cost/kWh tracking, user reviews, favorite stations
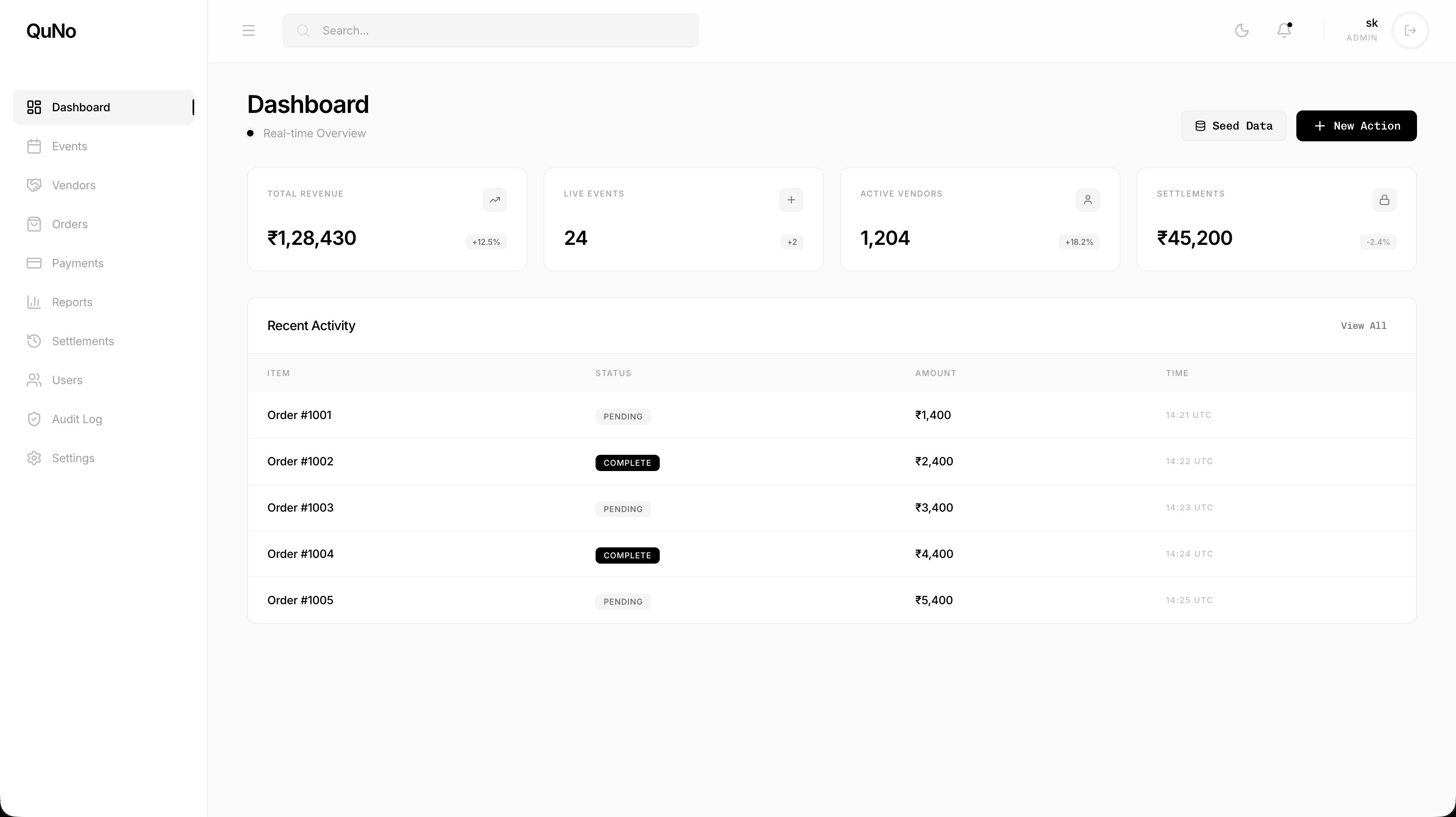
Events company with dozens of vendors. Orders in spreadsheets, manual payment reconciliation, settlements taking days, no audit trail. Full day of reconciliation after every event.
8 modules: Events, Vendors, Orders, Payments, Settlements, Reports, Users, Audit Log. Real-time Firebase dashboard. Automated settlement calculations. Full audit trail with role-based access.
- Live metrics via Firebase listeners: revenue, events, vendors, settlements
- Configurable commission rates per vendor/event/category
- Multi-currency support, tax computation, invoice generation
- RBAC: Admin, Finance, Event Manager, Vendor, Read-Only
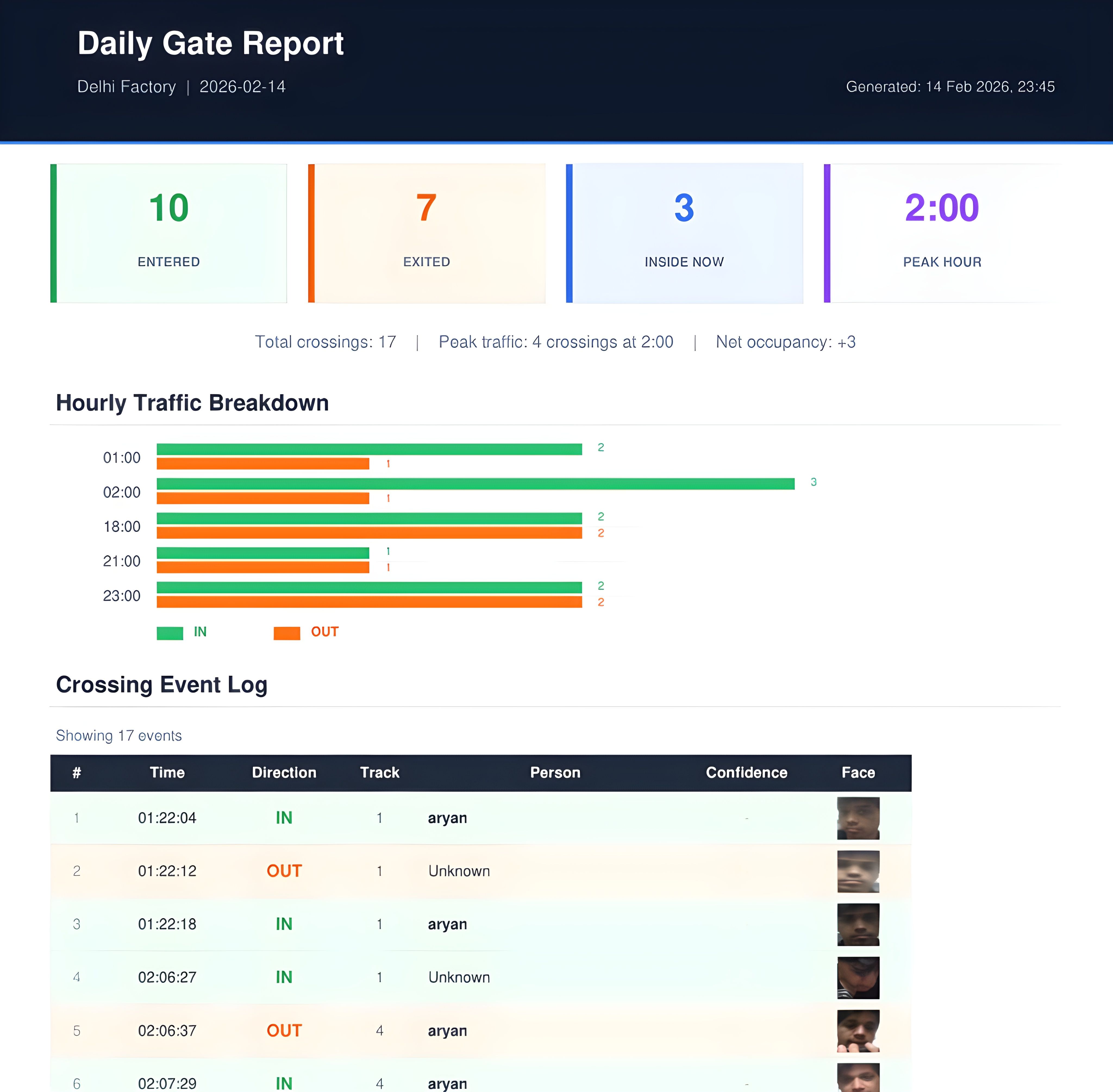
Industrial facilities with 350+ workers. Manual gate registers, no PPE compliance tracking, no zone violation detection, hours of weekly safety reconciliation. Zero real-time occupancy or safety visibility.
Desktop application powered by open vision models, processing live camera feeds through a deep learning pipeline. PPE detection (helmet, vest), restricted zone monitoring, person tracking with IN/OUT counting. All data in SQLite. Daily PDF + Excel reports auto-emailed. No cloud, no servers, no internet required.
- Live video with bounding boxes, track IDs, PPE status labels
- Restricted zone polygons with configurable boundaries and violation alerts
- Employee management: register via camera or photo upload
- System tray operation, Windows auto-start, single .exe via PyInstaller
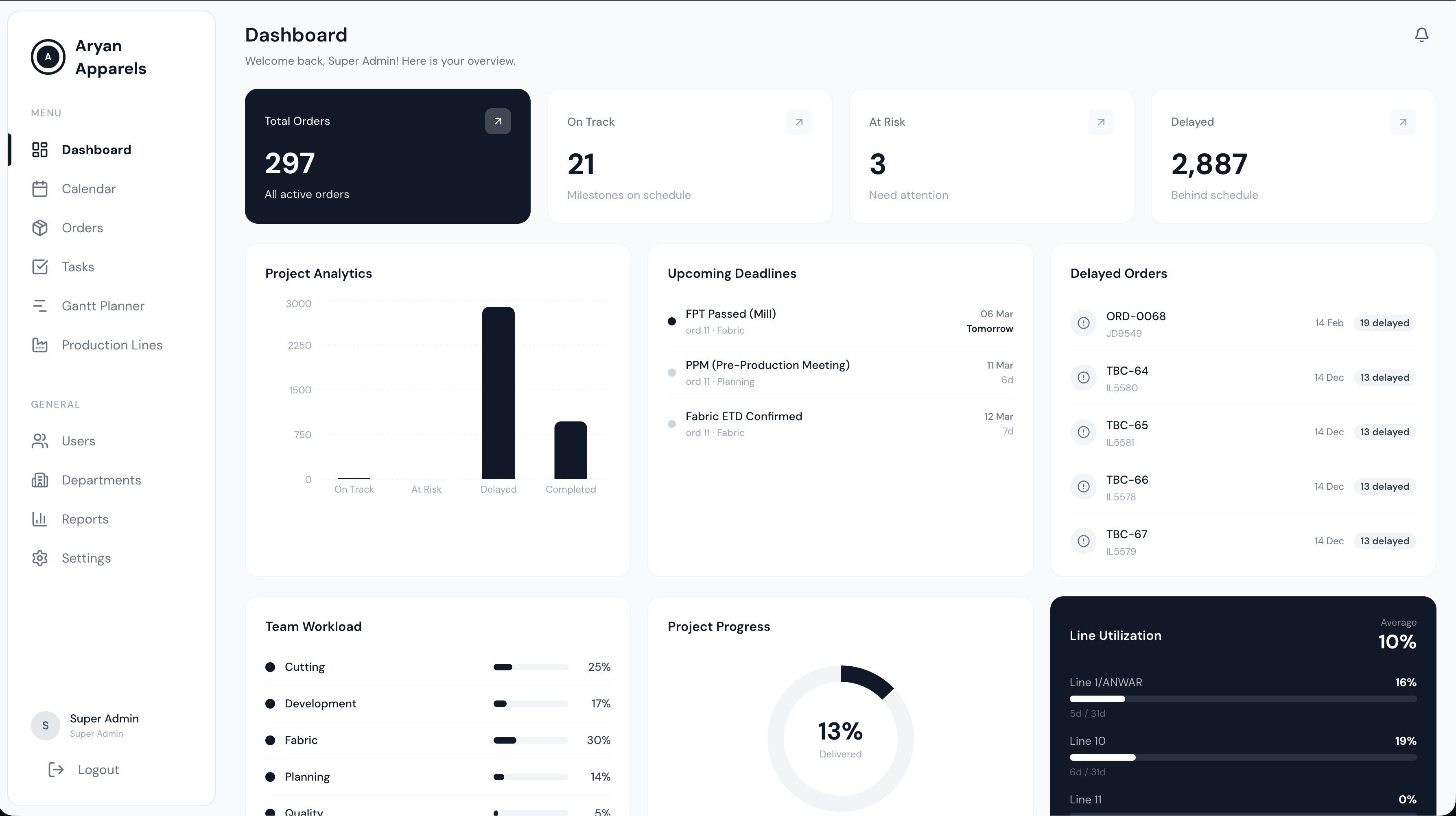
Garment manufacturers producing for Adidas, Nike, and Reebok track 295+ production orders across 9 departments using Excel spreadsheets. No automated milestone planning, no quality gate enforcement, no capacity simulation, and no real-time visibility into production delays or line utilization.
Dual-track milestone engine with SOP quality gates and capacity simulation. Track A computes backward milestone dates from CRD offsets. Track B triggers milestones from events like GRN receipt. 9 mandatory pre-cutting SOP quality gates with evidence uploads and override tracking. Capacity engine with production day calculation, LPCD computation, and what-if simulation with overtime. Custom Gantt chart, FullCalendar, Kanban + table task views, Excel import via SheetJS, and Recharts analytics.
Dual-track: Track A (CRD offset dates) + Track B (event-triggered by GRN receipt). 3,245+ auto-generated milestones across 295 real production orders seeded from 9 departments.
9 mandatory pre-cutting quality gates with evidence uploads, override tracking, and audit trail. Gates block production progression until satisfied.
3-tier RBAC: Super Admin, Manager (HOD), Employee. 14 routes, 31+ API endpoints. GitHub Actions CI: lint, typecheck, test, build.
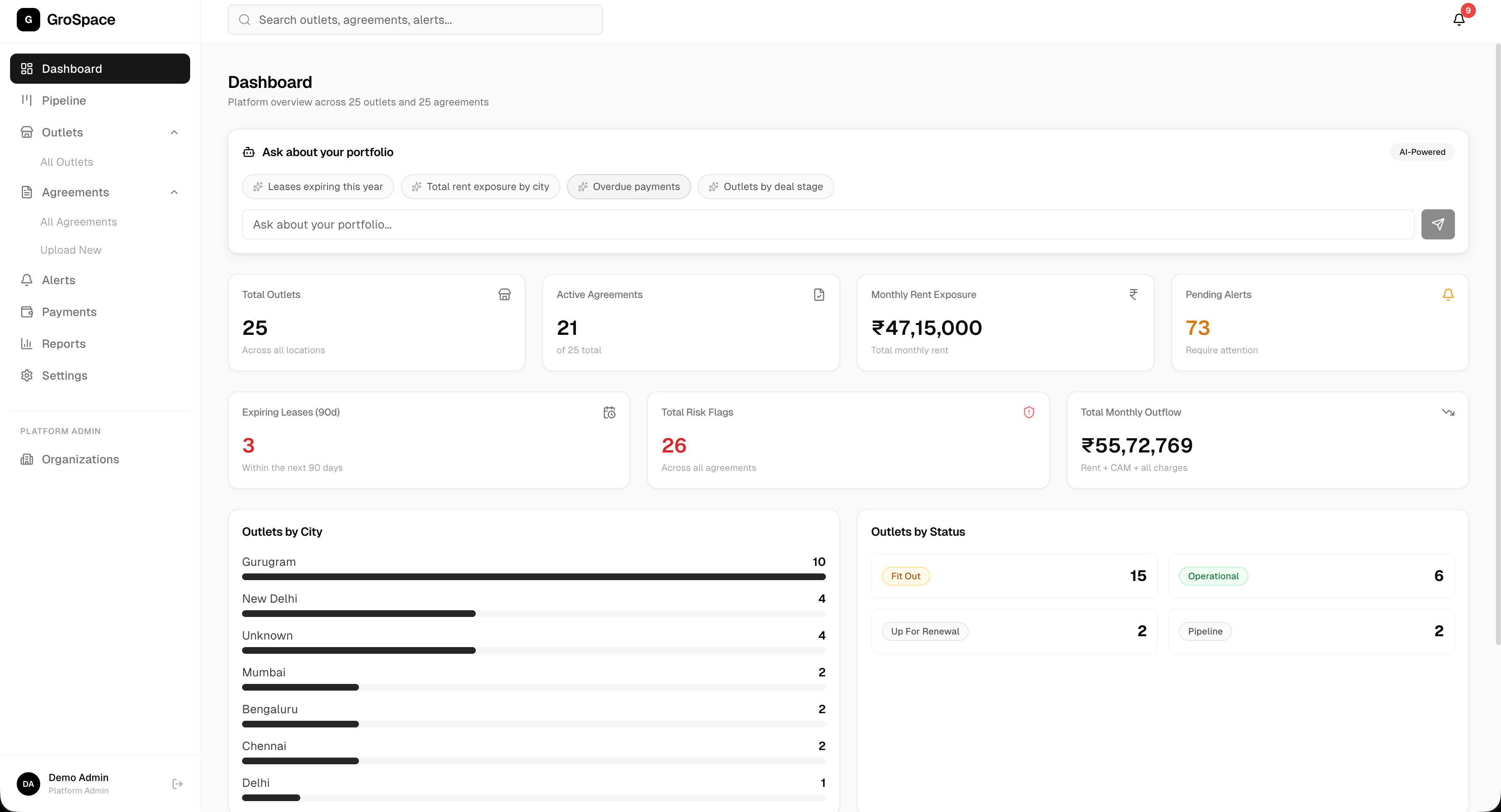
Multi-brand retail operators managing 50-500+ outlets (Blue Tokai, Domino's, McDonald's, Burgerama, Enoki) track lease agreements manually. Extracting structured data from scanned/handwritten PDFs, tracking obligations, managing payments across rent models, and flagging risks requires manual review of every document.
AI extracts 60+ structured fields from lease PDFs via Gemini 2.5 Pro (text + scanned/handwritten). Confirm & Activate flow auto-creates outlets, obligations, alerts, and payment schedules. 6-stage deal pipeline with drag-and-drop Kanban. Smart AI chat for natural language portfolio queries. Payment generation with escalation across 4 rent models. Notification routing via Resend (email) + MSG91 (WhatsApp) per alert type.
Gemini 2.5 Pro extracts 60+ lease fields from text and scanned PDFs (vision mode for handwritten documents). Structured output validated and mapped to 12 DB tables with Supabase RLS.
Single-click flow auto-generates outlets, obligations, 11 alert types, and payment records from extracted lease data. Multi-org RBAC with Supabase Row Level Security.
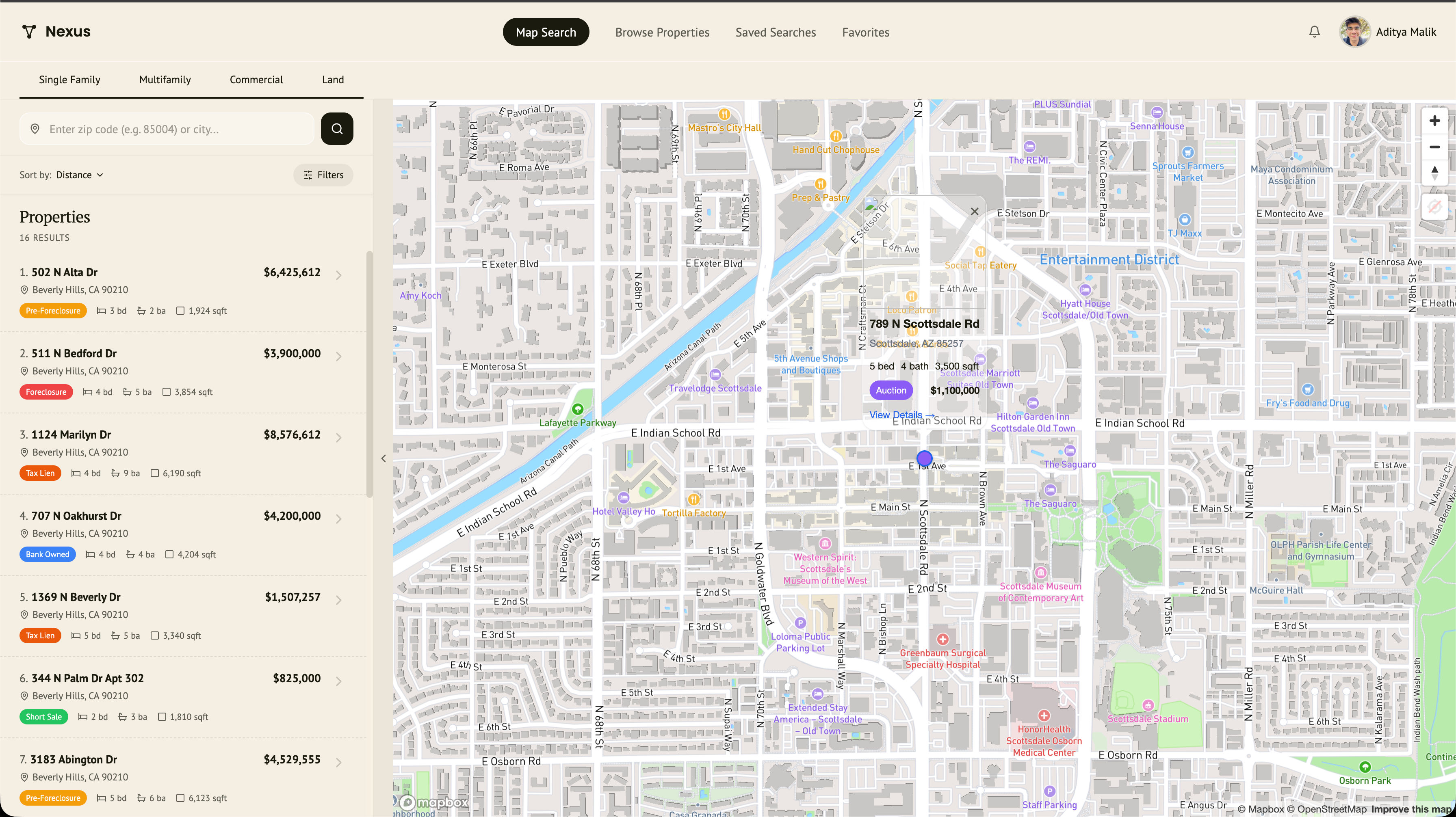
Real estate investors manually scout distressed properties across county records, MLS listings, and probate filings. No unified platform to discover, score, underwrite, and structure deals on foreclosures, tax liens, and land parcels for data centers and renewable energy installations.
4 AI agents powering a Scout, Underwrite, Outreach, Deal Structure pipeline. 13-rule distress detection engine with tier-1 definitive and tier-2 probabilistic signals. XGBoost ML scoring (0-100% investment score). Claude underwriting agent generates Buy/Pass/Watch briefs. Claude deal structuring agent selects from a 9-strategy library. 3D Mapbox with Street View popups. Subscription tier gating across SFR, multifamily, commercial, and land.
3 parallel data providers: ATTOM (8 API endpoints), RESO MLS (OData client), Probate (signal-based detection). 13-rule distress classification across 2 tiers.
XGBoost on Flask for distress scoring (11 features). Claude agents for underwriting briefs and deal structuring from 9-strategy library.
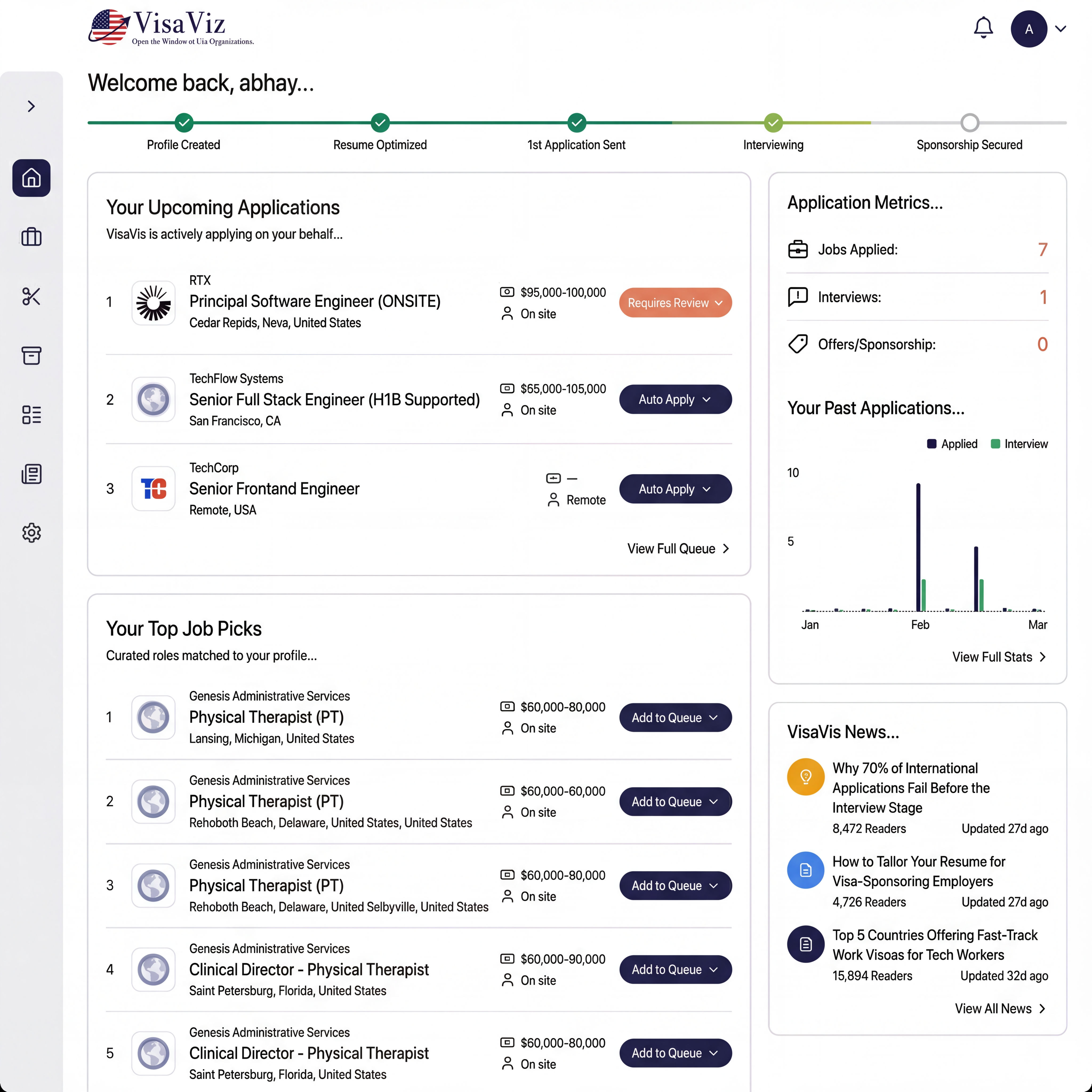
Job seekers spend hours manually filling out repetitive application forms across different ATS platforms. Each platform (Lever, Greenhouse, Workday) has different form structures, and aggressive bot detection systems (hCaptcha, reCAPTCHA, Cloudflare) block automated submissions.
5-tier CAPTCHA bypass with multi-ATS automation. Stealth Chromium with Chrome runtime spoofing, WebGL/Canvas fingerprint masking, and 150+ anti-detection scripts. Human behavior simulation (random delays, natural mouse movements, typing patterns). ATS-specific adapters for Lever and Greenhouse with form field mapping and resume upload. 2Captcha and Bright Data integration for fallback solving. Browser profile persistence for session reuse.
Tier 1: Chromium + stealth + profile reuse (~40%). Tier 2: Firefox fallback (~30%). Tier 3: 2Captcha solver at $0.003/solve (~95%). Tier 4: Bright Data scraping browser at ~$0.10 (~99%). Tier 5: Manual review (100%).
Abstract base adapter with smart form-filling utilities, error classification, and screenshot capture at each stage. Lever and Greenhouse adapters handle multi-page forms, custom questions, and resume uploads.
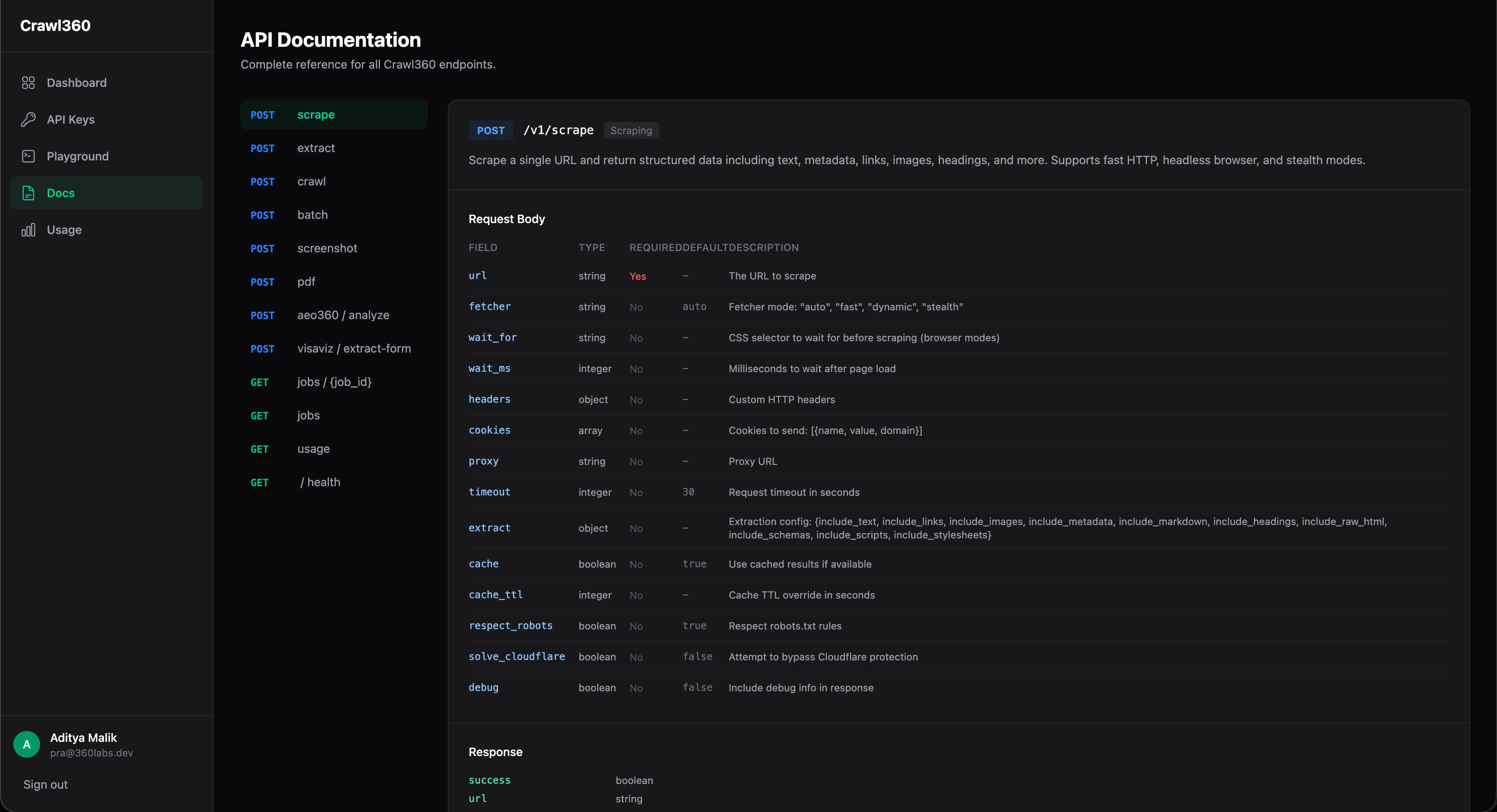
Web scraping is fragmented across dozens of tools. SPAs need headless browsers, anti-bot sites need stealth mode, and there is no unified API that handles scraping, extraction, crawling, screenshots, PDFs, and SEO audits in one platform with automatic escalation.
One API, seven capabilities. Single-page scrape with auto-escalating fetcher (fast > dynamic > stealth). CSS/XPath structured extraction. Multi-page crawl (up to 50 pages, 5 levels deep) with async job polling and webhooks. Screenshot capture (PNG/JPEG, full-page). PDF generation (A4/Letter/Legal). AEO360 full-site SEO audit. Batch scraping up to 100 URLs in parallel. Cloudflare bypass, proxy support, robots.txt compliance, and response caching built in.
Three modes: Fast (HTTP client, ~100ms), Dynamic (headless Chromium), Stealth (anti-detection). Auto mode escalates on failure. Per-request config for wait selectors, custom headers, cookies, and proxies.
RESTful v1 API with API key auth, rate limiting, admin approval flow. Async jobs for crawl and batch operations with poll URLs and webhook callbacks. Response caching with configurable TTL.

NLU trilemma: accuracy (cloud), speed (rules), or small footprint (simple classifiers), never all three. Cloud NLU: 250ms+ latency, connectivity required, privacy concerns. Rasa: ~500MB, 93-96% accuracy.
Hybrid classification: fast pattern matching (<1ms) + semantic embeddings (39ms) with confidence arbitration. Multi-step reasoning, 5-tier SmartMemory, predictive context, entirely on-device in 50MB.
Fast Path: compiled regex + keywords (<1ms). Semantic Path: quantized 32MB ONNX model, 384 dims (~35ms). Arbitration layer selects best result.
- Short-term (session), Episodic (past interactions), Semantic (domain knowledge)
- Procedural (learned sequences), Meta-learning (self-improving thresholds)
| Metric | SLM360 | Rasa | Dialogflow |
|---|---|---|---|
| SNIPS | 98.0% | ~96% | ~97% |
| Banking77 | 100.0% | ~93% | ~94% |
| Latency | 39ms | ~150ms | ~250ms |
| Memory | 50MB | ~500MB | Cloud |
AI applications have no long-term memory. Every conversation starts from scratch. Users repeat preferences, context is lost between sessions, and personalization is impossible without a structured memory system.
A clean pipeline: conversation > LLM extraction > embedding > vector storage > semantic retrieval > prompt injection. Pluggable at every layer. Works as Python SDK, REST API, or CLI.
LLM extracts long-term facts > validation (confidence >= 0.6, <= 200 chars, bad pattern filtering) > deduplication (cosine similarity >= 0.85 triggers merge/skip) > embed to 384-dim vector > upsert to storage backend.
Embed query > vector search (filtered by user + status=active) > re-ranking: 0.6 x relevance + 0.3 x confidence + 0.1 x recency > return top K results.
Calls search(), formats results into a system prompt preamble: "You know the following about the user: ..."
Created (conf 0.9) > Accessed (count++, last_accessed updates) > Decayed (conf x 0.95 if unused) > Archived (conf < 0.6) > Deleted (soft, recoverable).
| Layer | Options | Default |
|---|---|---|
| LLM | OpenAI, Anthropic, Groq, Ollama, Custom | - |
| Storage | In-Memory, JSON, SQLite, Qdrant | In-Memory |
| Embeddings | Local (MiniLM-L6-v2), OpenAI, Custom | Local (384-dim) |

Three critical gaps in medical AI for India: (1) no Indian medical context, (2) zero Hinglish support, (3) unfamiliarity with Indian pharma brands (Crocin, Calpol, Combiflam). No off-the-shelf model addresses all three.
Fine-tuned Gemma 3 4B on 173K+ curated medical examples across three stages. Natively understands Hinglish, knows Indian drug brands, trained on 44K+ AIIMS/NEET-PG questions. Edge-optimized at $0.001/query.
- Stage 1 (23,400): Foundational: anatomy, physiology, pharmacology
- Stage 2 (95,729): Reasoning: differential diagnosis, drug interactions
- Stage 3 (54,007): Indian context: Hinglish, Indian pharma, regional diseases
Automated metrics inversely correlated with clinical utility. 30.7% on benchmarks vs. Gemma's 38.8%, yet more accurate in real-world clinical evaluations.

LLM-based multi-agent systems are vulnerable to deadlock through the four Coffman conditions: mutual exclusion (API keys, tool slots), hold-and-wait, no preemption, and circular wait. Existing solutions (max_iterations, timeouts) don't provide mathematical guarantees.
| Gap | Problem | Solution |
|---|---|---|
| Silent Stalls | Agents freeze with no detection | Progress Monitor with named metrics + auto reclamation |
| Authority Deadlocks | Delegation chains form cycles | Delegation Tracker with BFS/DFS cycle detection |
| Unknown Demands | Can't predict max resource needs | Adaptive Demand Estimator with statistical learning |
ResourceManager orchestrator with SafetyChecker (Banker's Algorithm), RequestQueue, 5 scheduling policies (FIFO, Priority, ShortestNeedFirst, DeadlineAware, Fairness), ProgressTracker, DelegationTracker, DemandEstimator.
Direct integration with LangGraph/LangChain. Wrap tools with @guarded_tool decorator for automatic resource management.
Prompts scattered across documents. No version tracking, regression testing, or cross-model comparison. Every update was a guess with no quality metrics.
Prompts as Code. Markdown + YAML frontmatter, JSON test fixtures, bulk evaluation with pass/fail. A/B testing with 95% confidence intervals via bootstrapped sampling. Local React dashboard for traces and cost analysis.
Markdown with YAML frontmatter (model, temperature, version). Git-tracked project structure with diff-based analysis.
Four assertion types: exact match, regex, semantic similarity (cosine distance), JSON schema. Parallel execution across providers.
- Google Gemini (1.5 Flash > 3.0 Pro), OpenAI (GPT-4o, GPT-4), Anthropic (Claude), Ollama (local)
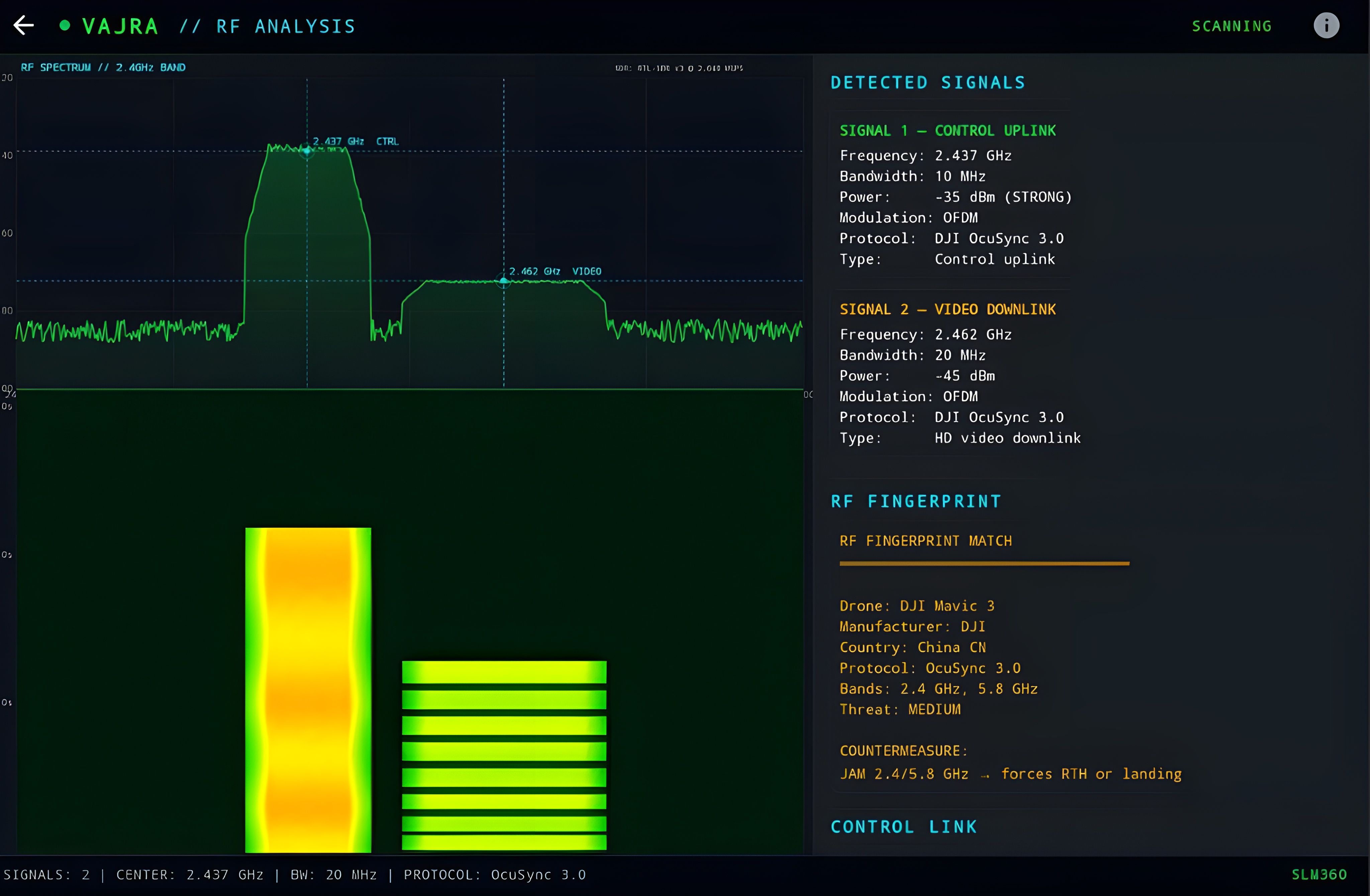
Current counter-drone systems cost $500K-$5M per installation, require dedicated radar arrays, persistent network connectivity, and fixed infrastructure. Impractical for forward-deployed military positions, border posts, or mobile patrols in denied/degraded communications environments.
Complete C-UAS pipeline on a single Android device. Three detection modalities: visual (camera + custom-trained YOLOv8n, 12MB), acoustic (microphone + FFT + custom-trained CNN, 129KB), and RF spectrum analysis. All fused into a unified tactical threat display with countermeasure control. All ML inference runs locally via TensorFlow Lite.
Custom-trained YOLOv8n (nano) on drone-specific imagery. 320x320 input, 2100 anchor boxes, float16 quantized. Real-time inference at >25 FPS on mid-range Android.
Dual-layer: real-time 1024-point FFT for propeller frequency detection (50-500 Hz) with harmonic validation, plus CNN classifier on mel spectrograms for drone type classification across 5 classes.
8 profiles (DJI Mavic 3, Bayraktar TB2, Shahed-136, FPV Attack, Fiber-Optic FPV, Orlan-10, Heron TP, DJI Phantom 4) with 22 parameters each covering identity, performance, RF/acoustic signatures, and threat assessment.
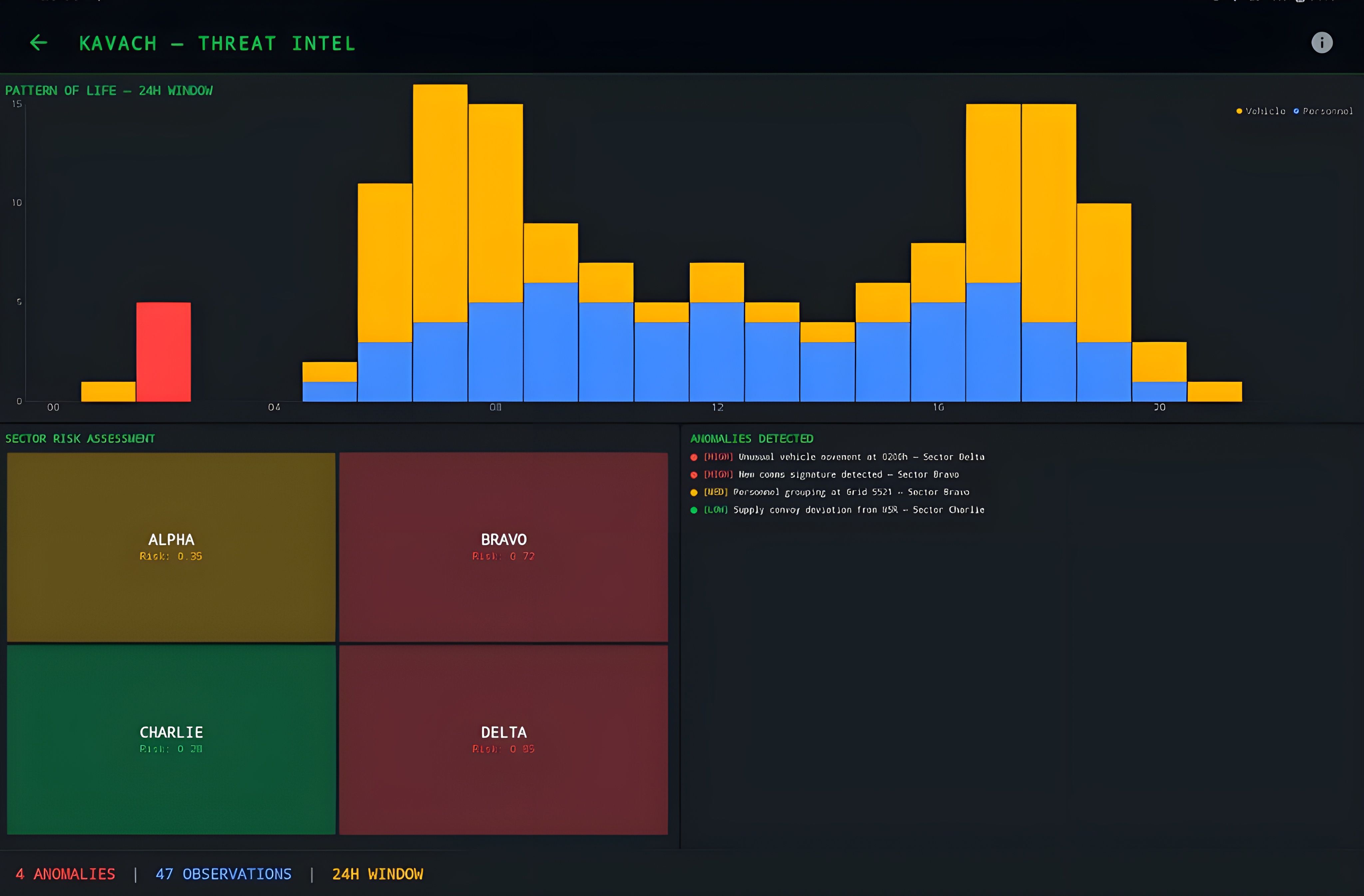
Existing C2 systems (ATAK, CPOF, Palantir TITAN) require persistent network connectivity, dedicated server infrastructure, and cost $500K-$M+ per node. Inoperable at the tactical edge in denied/degraded communications environments where squad-level units need real-time situational awareness and decision support.
Seven AI-powered modules on a single Android device. Tactical C2 with natural language commands (25 intents, <50ms), Data Fusion knowledge graph, ISR Processing (YOLOv8n, ~19 FPS), Auto SITREP (SALUTE reports in ~8s), Patrol Optimization (threat-aware routes in <3s), Threat Intel, and SLM360 Engine. All inference on-device via TensorFlow Lite.
NanoEncoder (6-layer transformer, 384-dim) + BaseDecoder (2-layer classifier). 577K parameters, 848KB INT8 quantized. Classifies 25 tactical intents in <50ms with entity extraction for grid coordinates, callsigns, and threat types.
Custom-trained YOLOv8n for PERSONNEL and VEHICLE detection at ~19 FPS. Tactical overlay with confidence scores, detection log, and real-time statistics.
AI-generated SALUTE reports (Size, Activity, Location, Unit, Time, Equipment) from current tactical picture in ~8 seconds. Three report types: SITREP, Threat Report, Patrol Report.
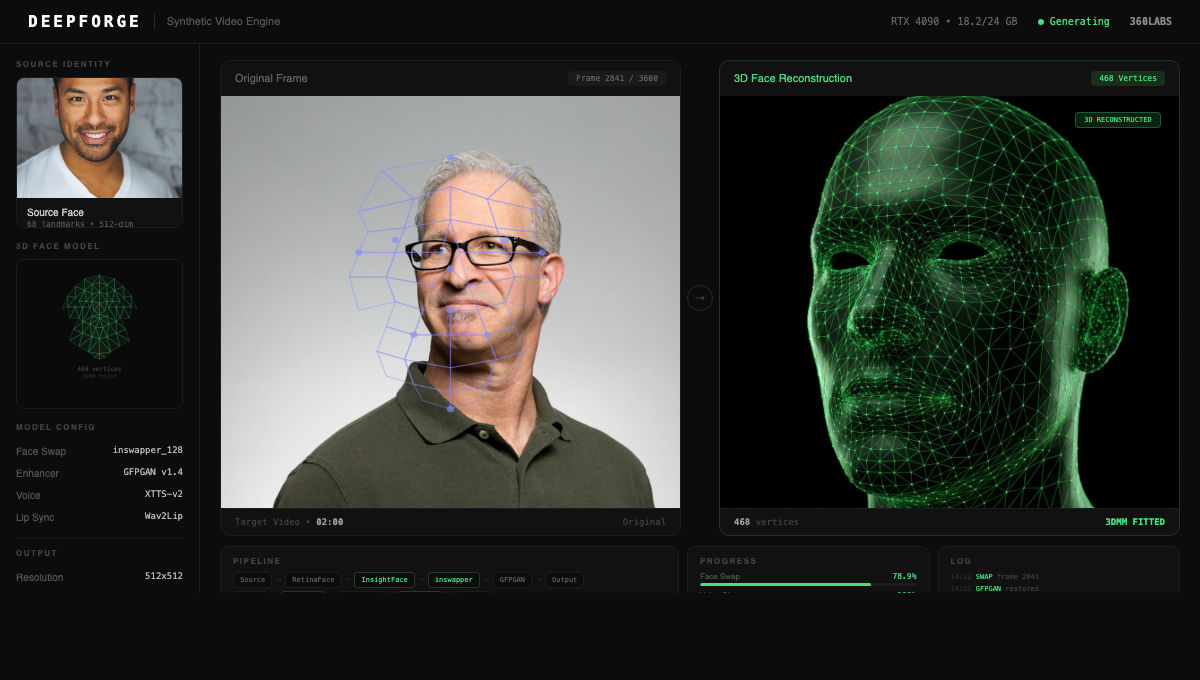
Open-source deepfake models (InsightFace, Wav2Lip, GFPGAN, Coqui TTS) exist as isolated tools with no unified pipeline, no quality scoring, and no production-grade video output. Combining face-swap + voice clone + lip-sync into a coherent video requires custom orchestration, A/V synchronization, and frame-level quality control that no single tool provides.
DeepForge orchestrates open-source models into a unified 5-pipeline video generation engine. Face-swap via InsightFace + inswapper_128 with GFPGAN/CodeFormer restoration. Voice cloning via Coqui XTTS-v2 (467M params, 30s reference). Lip-sync via Wav2Lip aligning cloned audio to swapped faces. Full video generation fusing all outputs at 512x512, 30 FPS. Detection adversary scoring output against anti-deepfake classifiers.
RetinaFace detection, InsightFace 512-dim embedding, inswapper_128 face replacement, GFPGAN face restoration (70M params). Poisson seamless blending. Temporal consistency across frames. Output: 512x512, 30 FPS, 33ms/frame.
Coqui XTTS-v2 (467M params) for multilingual voice cloning from 30s reference. HiFi-GAN vocoder (14M params). Wav2Lip (12M params) synchronizing generated speech with facial keypoints for accurate mouth movement.
End-to-end orchestration: face-swap + voice clone + lip-sync fused into a single output. Frame-level A/V sync, lighting normalization, H.264 encoding. Batch processing with queue management for multi-clip workflows.
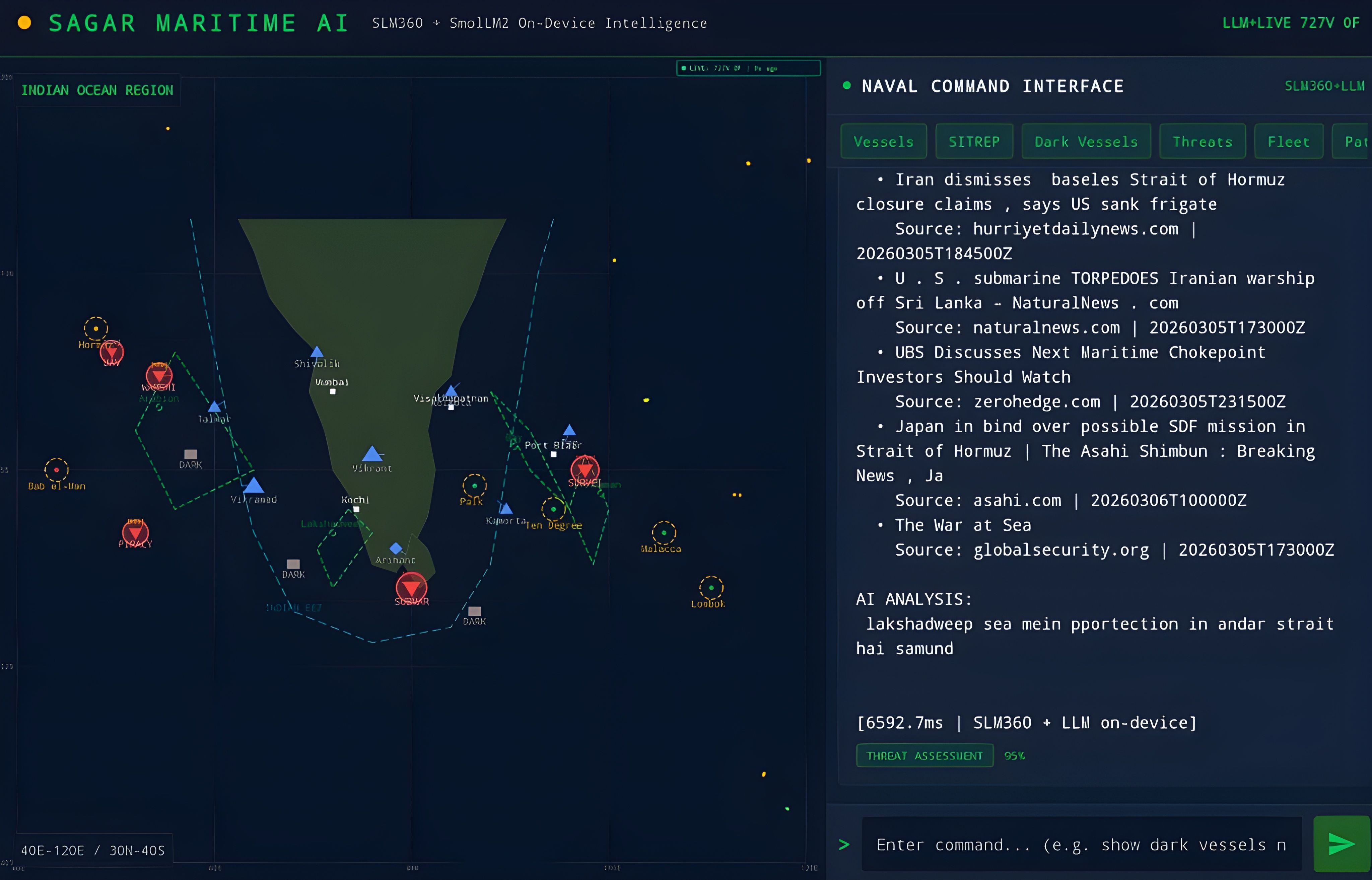
Existing naval C2 systems depend on persistent network connectivity and cloud infrastructure. In contested maritime environments, connectivity is unreliable or denied. Commanders need AI-powered decision support that works on-device, handles Hindi-English (Hinglish) commands, and fuses vessel, aircraft, weather, and OSINT data into a unified tactical picture.
Seven core capabilities on a single Android device. Maritime C2 Console with split-screen tactical map and AI chat (English + Hinglish). On-Device AI with SLM360 NanoEncoder (~ms, 30 intents) and SmolLM2-360M (386MB) for narrative briefs. Live data from AIS, OpenSky, GDELT/RSS, and weather APIs. Intel Alerts with FLASH/URGENT/ROUTINE/LOW triage. AI Insights for threat assessments. Offline mode with cached data. Tactical Map with vessel positions, dark vessels, chokepoints, and flight tracks.
All inference on-device, zero cloud calls. SLM360 NanoEncoder for ultra-fast intent classification across 30 naval intents. SmolLM2-360M for optional narrative briefs and threat summaries.
Dark tactical theme, military report formats (DTG, SITREP), classification banners, split-screen C2 layout. Mixed Hindi-English commands ("vessels dikhao", "khatre batao").
AIS, OpenSky, GDELT + RSS (OSINT), and weather APIs fused into a unified tactical picture. Offline mode caches last-known state with staleness indicators.
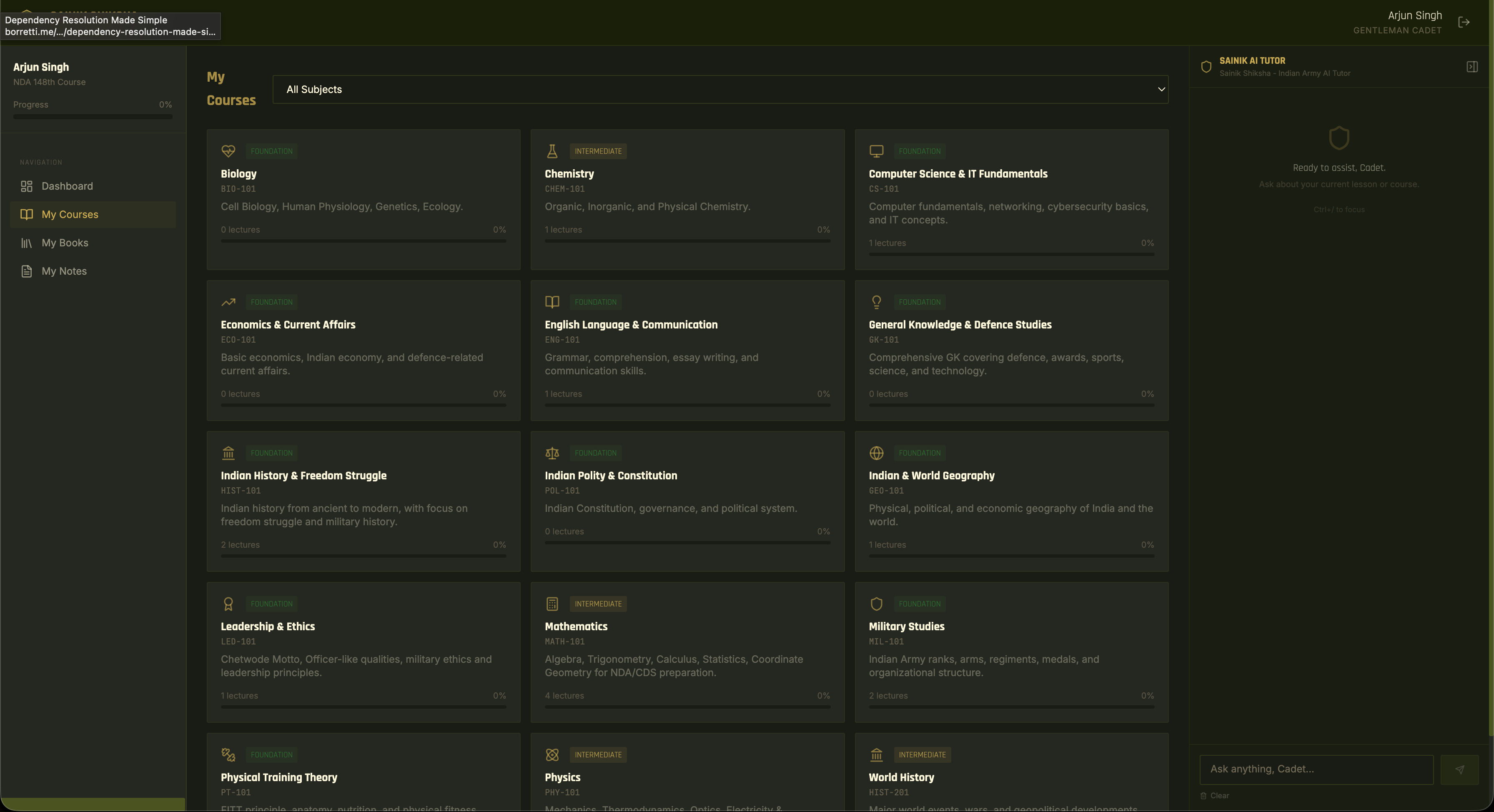
Military training academies lack a modern, AI-integrated learning platform tailored to the Indian Army context. Generic LMS tools offer no military persona, no context-aware tutoring, and no themed experience for cadets preparing for NDA, IMA, and OTA.
Full-stack military education platform with a streaming AI tutor. 3-column cadet layout with nav, content, and AI tutor panel. SAINIK AI streams responses via SSE with a senior officer persona, context-aware of the current course/lecture. Course enrollment, lecture progression, in-app PDF reader (60-240% zoom), personal notes, and a dashboard with daily army quotes. Admin command center with CRUD for cadets, courses, lectures (4 types), and books (50MB PDF upload).
Cadet message flows through build_full_context() pulling course/lecture/notes from DB, build_system_prompt() injecting cadet profile + military persona, CadetMemoryManager (last 40 messages), then Groq API (LLaMA 3.3-70B, temp=0.3). SSE token stream renders live in Redux. Frontend scrapes visible DOM text (1,500 chars) so the AI sees what the cadet sees.
FastAPI (async Python 3.12), SQLAlchemy 2.0 + asyncpg, PostgreSQL 16, 8 DB models, 9 API route groups. JWT (15-min) + HttpOnly refresh cookie (7-day), bcrypt, role enforcement at every endpoint.
React 18 + Vite 5, Redux Toolkit, TailwindCSS. react-pdf book reader, Recharts admin charts. Docker Compose (3 services), Railway-compatible.
Palantir proved that a single engineering company can become the operating system for institutions at scale. They embedded with customers, learned what entire industries needed, then productized the patterns. $250B company.
We aspire to be that for India. The team that top institutions, government ministries, and enterprises rely on for their most critical software and AI infrastructure. We have the technical capacity across the full stack: foundational AI research, model training, product development, and hands-on implementation. What we look for are partners who bring domain expertise and the ambition to co-build something useful together.
Every client engagement teaches us what an entire sector needs. Every deployment becomes a pattern. Every pattern becomes a product. The consulting funds the R&D. The R&D becomes the product. The product funds the next generation.
That's our flywheel.
Full stack ownership. Application layer, models, memory, data, deployment. We pick the right tool for the problem, every time.
Inherent lower costs. Every system we build creates reusable IP. The 10th deployment costs a fraction of the first.
Speed. Prototypes in 24 hours. Production systems in 2-8 weeks. Government compliance baked in.
The 23 projects in this document are proof of a thesis: when you compress research, engineering, and deployment into one team, the output quality goes up and the timeline collapses.
We're looking for organizations that want a technical partner who understands the constraints, cares about the outcome, and will be in the room when the system goes live.
If you're looking for a young, hungry and deeply AI-native tech team.
Lightyear 360 Labs Pvt Ltd